
La data science au service des administrations
7. La détection d’anomalies
Une administration chargée de fournir des prestations financières à des individus doit également s’assurer de l’exactitude des prestations accordées, ainsi que de la qualité des données sur lesquelles reposent leurs calculs. En effet, l’égalité et la légalité de traitement des bénéficiaires ne sauraient être garanties sur la base de données erronées. Cependant, Il est impossible pour les auditeurs d’examiner les centaines de milliers de prestations et ceux-ci doivent généralement se contenter d’un petit échantillon aléatoire.
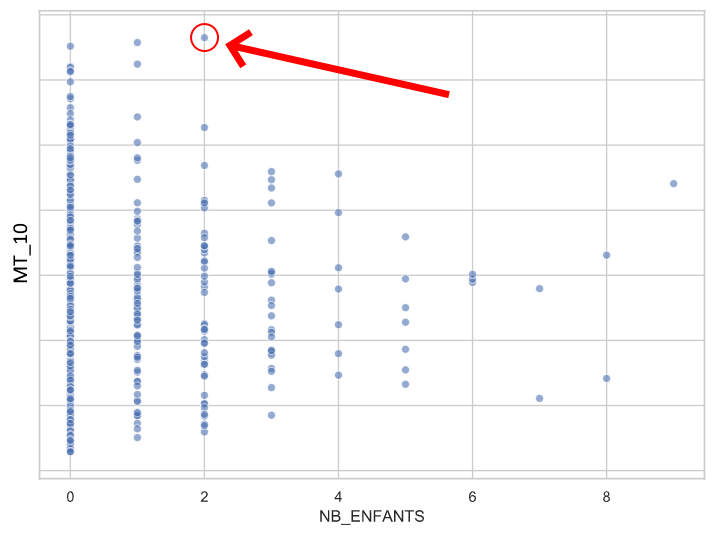
L’exercice vise donc à fournir un échantillon sélectionné de façon plus pertinente. L’algorithme repose ici sur un jeu de données fictif et similaire à ce qu’une administration cantonale peut récolter. Une approche est la détection d’anomalies, qui est traditionnellement réalisée en analyse univariée. Par exemple, il peut être intéressant de prioriser son attention sur les prestations anormalement élevées, ou encore sur des bénéficiaires qui ont un grand nombre d’enfants. Il est également possible d’observer des anomalies sur plusieurs dimensions. Par exemple, croiser les distributions du nombre d’enfants et d’un montant déclaré par les bénéficiaires révèle un enregistrement isolé parmi les familles à deux enfants.
Histogramme et box-plot de la répartition du nombre d’enfant des bénéficiaires

Distribution croisée d’un montant selon le nombre d’enfants
Grâce au machine learning, il est désormais possible de détecter également des anomalies sur un grand nombre de dimensions. Malgré tout, une ligne anormale n’indique pas forcément une prestation erronée et il appartient in fine aux professionnels d’évaluer la performance du modèle en vérifiant les résultats sur le terrain. Parallèlement, dans ce scénario, il apparaît que plusieurs inexactitudes détectées dans le passé résultaient d’erreur de saisie du nom des bénéficiaires.
Les hypothèses de travail
- Plus une ligne contient un score d’anomalie élevé, plus il y a de chance qu’il s’agisse d’une prestation inexacte.
- Plus une paire de lignes contient des noms similaires et plus ces lignes partagent des valeurs identiques, plus il y a de chances qu’il s’agisse de doublons concernant un même bénéficiaire.
7.1. Algorithme de détection d’anomalies
7.1.1. Importation des librairies et des données
L’exemple s’appuie sur des données fictives de 1000 prestations versées à 953 bénéficiaires différents.
Les colonnes du jeu de données
- DOSS – le numéro de dossier
- NOM – le nom du bénéficiaire
- AGE – l’âge du bénéficiaire
- A_UN_CONJOINT – si le bénéficiaire a un conjoint (True) ou non (False)
- NB_ENFANTS – le nombre d’enfants du bénéficiaire
- AVS – si le bénéficiaire perçoit une rente AVS (True) ou non (False)
- AI – si le bénéficiaire perçoit une rente AI (True) ou non (False)
- MT_# – les 10 différents montants déclarés (perçus ou dépensés) du bénéficiaire
- DATE_… – Les dates de début, de fin et d’écriture de la prestation
# ==========================
# Importation des librairies
# ==========================
# Traitement
import pandas as pd
import numpy as np
import Levenshtein
# Visualisation
import matplotlib.pyplot as plt
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
# Machine Learning
from sklearn.ensemble import IsolationForest
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
# =======================
# Importation des données
# =======================
# Lit le fichier
df = pd.read_csv('fake_SPC.csv')
# Convertit les colonnes date en format date
cols_to_date = ['DATE_DEBUT', 'DATE_FIN', 'DATE_CREA']
for col in cols_to_date:
df[col] = pd.to_datetime(df[col])Exemple de quelques lignes et colonnes du jeu de données fictif

7.1.2. Feature engineering
Le feature engineering consiste à créer de nouvelles colonnes à partir d’informations implicitement présentes dans le jeu de données (Brownlee 2014). Ce processus présente deux utilités majeures : 1) il apporte des informations que le modèle ne reconnaît pas de lui-même ; 2) il permet d’utiliser des modèles moins complexes (et ainsi plus compréhensibles). Par exemple, il est possible de compter le nombre de lignes (i. e. prestations) pour chaque bénéficiaire et découvrir de nouvelles valeurs extrêmes.
Distribution du nombre de lignes par nom
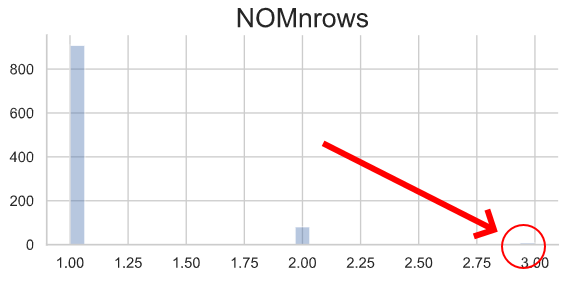
Le feature engineering relève plus de l’art que de la science et la quantité des informations générées dépend du temps consacré à les imaginer puis à les calculer.
Nouvelles colonnes (features) créées
- NOMnrows – le nombre de lignes par nom
- NOMmin_lev_score – la distance Levenshtein (ou d’édition) minimum entre un nom et les autres1La distance Levenshtein compte le nombre d’opérations d’édition nécessaire entre deux chaînes de caractères pour arriver à l’identité (Nam 2019). Par exemple, la distance Levenshtein entre banane et banana et égale à 1.
- NB_ENFANTSnuniques – le nombre de valeurs différentes dans le nombre d’enfants pour chaque nom
- NB_ENFANTSspan – l’étendue des nombres d’enfants pour chaque nom
- A_UN_CONJOINTnuniques – le nombre de valeurs différentes dans l’état civil pour chaque nom
- DATE_CREAdayofweek – le jour de la semaine où la prestation a été créée (lundi = 0 ; dimanche = 6)
- DATE_CREAis_restday – si la prestation a été un jour de repos (True) ou non (False) ‘duree_presta’ – la durée de la prestation
# ===================
# Feature engineering
# ===================
# Compte le nombre de lignes par nom
df['NOMnrows'] = df['NOM'].map(dict(df['NOM'].value_counts().reset_index().values))
# #####
# Calcule la distance Levenshtein (ou d'édition) entre les noms
# et attribue à chaque nom la distance minimale le concernant
strings = list(df['NOM'].unique())
min_lev = []
for string in strings:
other_strings = [s for s in strings if s is not string]
lev = [(string, other_string, Levenshtein.distance(string, other_string))
for other_string in other_strings]
min_lev.append(min(lev, key = lambda x: x[2]))
# Attribue le score à chaque nom
df['NOMmin_lev_score'] = df['NOM'].map(dict([(string, lev)
for (string, other_string, lev)
in min_lev]))
# #####
# Calcule, pour chaque nom, le nombre de valeurs différentes dans le nombre d'enfants
df['NB_ENFANTSnuniques'] = df.groupby('NOM')['NB_ENFANTS'].transform('nunique')
# #####
# Calcule l'étendue des nombres d'enfants pour chaque nom
df['NB_ENFANTSspan'] = df.groupby('NOM')['NB_ENFANTS'].transform('max') \
- df.groupby('NOM')['NB_ENFANTS'].transform('min')
# #####
# Calcule, pour chaque nom, le nombre de valeurs différentes dans l'état civil
df['A_UN_CONJOINTnuniques'] = df.groupby('NOM')['A_UN_CONJOINT'].transform('nunique')
# #####
# Calcule le jour de la semaine où l’entrée de la prestation a été créée
df['DATE_CREAdayofweek'] = df['DATE_CREA'].dt.dayofweek
# #####
# Vérifie si la prestation a été créée un jour de repos
GE_holidays = pd.read_csv("GEholidays.csv").apply(pd.to_datetime, format="%d/%m/%Y")
df['DATE_CREAis_restday'] = (df['DATE_CREA'].isin(GE_holidays)) \
| (df['DATE_CREAdayofweek'] >= 5)
# #####
# Durée de la prestation
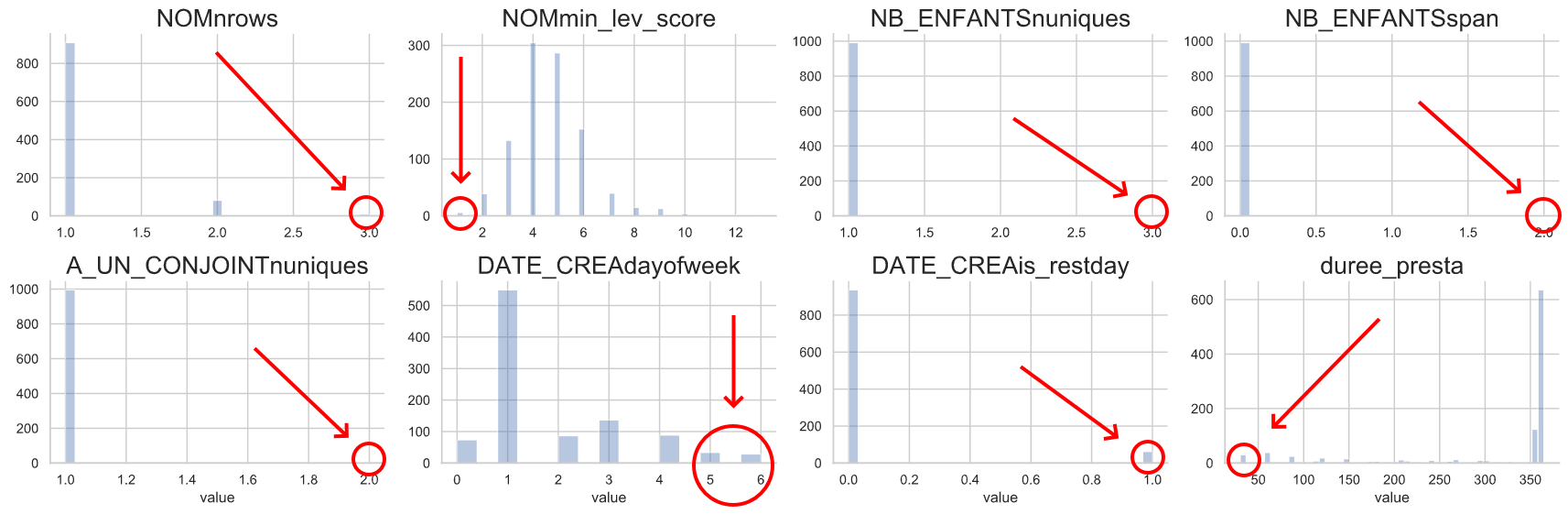
df['duree_presta'] = (df['DATE_FIN'] - df['DATE_DEBUT']).dt.daysL’analyse univariée de ces colonnes dévoile effectivement de nouvelles valeurs extrêmes ainsi que des informations étonnantes : par exemple, certaines prestations ont été créées un samedi, un dimanche ou un jour férié, ce qui semble incohérent avec les jours de travail usuels des administrations.
# Dessine la distribution des features créées
sns.set(style='whitegrid', rc={'figure.facecolor':'white'})
g = sns.FacetGrid(df.loc[:, 'NOMnrows':].melt(),
col='variable', sharex=False, sharey=False, aspect=1.5, col_wrap=4)
(g.map(sns.distplot, 'value', kde=False, norm_hist=False)
.set_titles("{col_name}", size=20))
plt.tight_layout(); Distribution des nouvelles colonnes
7.1.3. Préparation des données
23 colonnes du jeu sont retenues. Les identifiants et les dates (« DOSS », « NOM », « DATE_DEBUT », « DATE_FIN » et « DATE_CREA ») sont retirés, parce qu’ils ont des formats incompatibles avec le modèle.2S’il est possible de transformer ces valeurs pour qu’elles soient interprétables, cette opération ne sera pas réalisée ici, par souci de brièveté.
# ==================
# Data Preprocessing
# ==================
# Sélectionne les données compatibles avec le modèle
df = df.select_dtypes(include=['bool', 'float', 'int64']) Exemple de quelques lignes et colonnes des données prêtes pour l’entraînement
7.1.4. Modélisation
Le modèle choisi est l’Isolation Forest, un ensemble d’arbres de décision qui calcule un score d’anomalie pour chaque ligne (Liu, Ting et Zhou 2008). Le modèle repose sur l’idée que, plus un cas est rapidement isolable dans l’arbre de décision, plus il est considéré comme anormal.
L’algorithme Isolation Forest

Le modèle est paramétrable de diverses façons ; par défaut, les scores négatifs sont considérés comme des anomalies. La place du zéro dépend du nombre de lignes qu’on souhaite détecter (ici 2%, soit 20 prestations sur 1000).
# ============
# Modélisation
# ============
# Entraîne le modèle
model = IsolationForest(contamination=0.02,
n_jobs=-1,
random_state=42)
model.fit(df.values)
# Calcule le score d'anomalie de chaque ligne
df['IFanomaly_score']
\ = model.decision_function(df.values)
# Vérifie si le score est inférieur à zéro
df['IFanomaly'] = df['IFanomaly_score'] < 0Exemple de quelques lignes des scores d’anomalie

7.2. Algorithme de détection d’erreurs de saisie
La data science ne se résume pas à l’application de modèles de machine learning et la seconde hypothèse permet de l’illustrer. L’exercice consiste à calculer la similarité entre les lignes qui partagent des noms similaires : plus ces lignes partagent des valeurs identiques, plus elles ont de chances de révéler un même bénéficiaires indûment doublonné. L’hypothèse est testée selon le raisonnement suivant :
- Récupération des distances Levenshtein minimales (« NOMmin_lev_score ») pour sélectionner les paires de noms qui ne se distinguent que par une seule lettre.
- Pour chaque paire de noms, calcul du pourcentage de colonnes identiques.
- Affichage des paires de lignes les plus similaires.
# ===============================================================================
# Affichage des lignes aux noms similaires par pourcentage de colonnes identiques
# ===============================================================================
# Deux noms sont considérés similaires si leur distance Levenshtein
# est inférieure ou égale à 1
threshold = 1
similar_NOM = [triplet for triplet in min_lev
if triplet[2] <= threshold]
# Calcule le pourcentage de colonnes identique entre chaque paire de lignes
# et retient la paire avec le score le plus élevé
n_cols = len(df.columns)
max_sim_scores = []
for (string, other_string, _) in tqdm(similar_NOM):
rows1 = df[df['NOM'] == string]
rows2 = df[df['NOM'] == other_string]
for i in range(len(rows1.values)):
for j in range(len(rows2.values)):
tmp = []
similarity = np.sum(rows1.values[i] == rows2.values[j]) / n_cols
tmp.append((rows1.index[i], rows2.index[j], similarity))
max_sim_scores.append(max(tmp, key=lambda x: x[2]))
# Affiche les paires de lignes triées par pourcentage de colonnes identiques
pairs = pd.DataFrame(columns=df.columns)
for idx1, idx2, score in sorted(max_sim_scores, key=lambda x: x[2], reverse=True):
pair = df[df.index == idx1].append(df[df.index == idx2])
# Pour plus de lisibilité, on introduit une ligne de séparation
# entre chaque paire de lignes, dans laquelle est renseigné les indexes
# des lignes, ainsi le score de similarité entre ces deux lignes
sep_row = pd.DataFrame(np.zeros((1, len(df.columns))), columns=df.columns) \
.replace(0, '--') \
.rename(index={0: 'SIM'})
sep_row.iloc[0, 0] = f'{min(idx1, idx2)}|{max(idx1, idx2)}'
sep_row.iloc[0, 1] = f'{score*100} %'
pair = pair.append(sep_row)
pairs = pairs.append(pair)
# Retire les doublons dus à la symétrie du calcul de la similarité
pairs.drop_duplicates(inplace=True)Affichage des paires de lignes les plus similaires
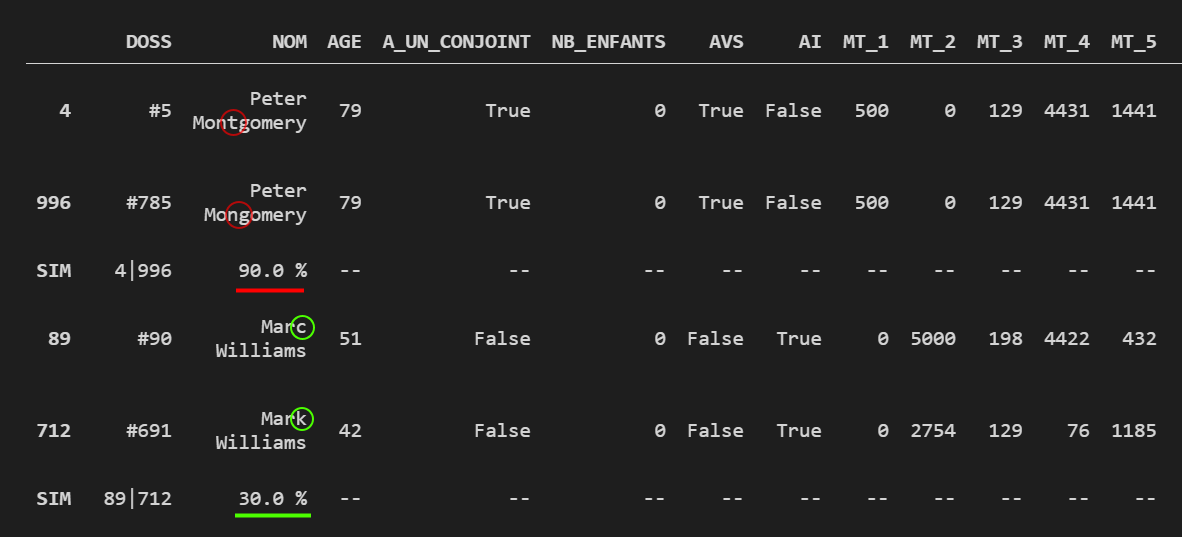
Cet outil permet non seulement d’identifier les noms les plus similaires, mais aussi de mettre en évidence les paires de lignes qui partagent le plus d’informations. Dans l’exemple ci-dessus, Peter Montgomery et Peter Mongomery sont considérés comme deux dossiers différents ; pourtant, 90 % de leurs colonnes sont identiques, dévoilant une probable erreur de saisie. À contrario, Marc Williams et Mark Williams ne partagent que très peu de valeurs, infirmant la possibilité d’une erreur de saisie.
Ces solutions restent cependant des solutions ex-post pour la qualité des données et des solutions préventives, comme l’aide à la saisie, pourraient contribuer plus efficacement à la qualité des données. À ce propos, le Competence Center Corporate Data Quality (CC CDQ) offre un résumé des scénarios d’application de machine learning pour la qualité des données (basé sur l’étude de 44 cas) :
Les scénarios d’application de machine learning pour la qualité des données

À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie