
La data science au service des administrations
2. Survol de la discussion scientifique
La thématique du big data en évaluation soulève plusieurs enjeux déjà explorés depuis une dizaine d’années. Dresser un état de la littérature permet de recenser les sentiers battus, ainsi que ceux qui restent à défricher. Néanmoins, la relative nouveauté du machine learning explique la pauvreté actuelle des publications liées à l’évaluation de projets, de programmes ou de politiques publiques. De plus, le machine learning est une pratique inhérente à la science des données (ou data science), une discipline nouvelle située à la frontière entre les statistiques et l’informatique (Christensson 2017). Malgré un lien déjà fortement établi entre les statistiques et l’évaluation, les professionnels du domaine peinent à intégrer ces nouveaux outils sans accuser un temps de retard (Bamberger 2017a).
2.1. Début des années 2010 : les premiers retours de terrain
Une première recherche de littérature dévoile cependant quelques contributions, issues essentiellement d’expériences d’intégration du big data au processus évaluatif. Les réflexions sur l’apport du big data et de ses applications dans la prise de décision ont très tôt émergé dans le développement international (UN Global Pulse 2012) (UNDP 2013) et, plus largement, en sciences sociales (Provost 2013). Plus tard, l’International Institute for Communication and Development (IICD) (2014, 6), fort des implémentations qu’il a dirigées, défend les bénéfices des nouvelles technologies au service de l’évaluation et propose quelques lignes directrices pour leur intégration. Parallèlement, Raftree et Bamberger (2014, 10) soulèvent le manque de preuves soutenant l’efficacité des nouvelles technologies de l’information et de la communication (NTICs), malgré une utilisation grandissante à toutes les étapes de l’évaluation. À contrario des réserves précédentes, Grimmer (2015) fait l’apologie du big data et du machine learning en tant que compléments des méthodes classiques en sciences sociales.
2.2. Le milieu des années 2010 : l’envol de la thématique
Quelques mois plus tard, le fameux site web Better Evaluation tente, dans un premier article, de synthétiser les connaissances de l’époque sur l’utilisation du big data en évaluation (Macfarlan 2015). Bien que la question apparaisse dans presque toutes les publications antérieures, l’article met en lumière les défis éthiques posés par la récolte massive d’informations. C’est à partir de cette période que l’United Nations Global Pulse publie ses premiers ouvrages de référence pour l’introduction des NTICs en évaluation, dans le but de familiariser les professionnels au big data et à son implémentation efficace dans un processus évaluatif (Jackson 2015) (UN Global Pulse 2016). Dès lors, la thématique prend son envol et les publications s’intensifient dans l’aide internationale, approfondissant toujours plus la question du recours au big data en évaluation (Mukarji 2016). Gustav Jakob Petersson (2017) publie le premier livre portant explicitement sur le big data et l’évaluation, en particulier sur l’usage du big data dans la production de connaissances fondées sur des preuves pour la prise de décision. Cet ouvrage est remarquable, car il exploite pour la première fois d’autres sources que les publications des organisations internationales. S’ensuivent quelques recherches très spécifiques sur l’usage du big data pour les évaluations ex-post (Netten 2017), sur la supériorité de l’approche bayésienne avec des flux continus de données (Finucane 2018) et sur l’application de la « double machine learning evaluation under uncounfoundedness » sur le marché du travail (Knaus 2020). Trois ans après sa première publication sur le sujet, Bamberger déplore le retard de l’évaluation en la matière et ouvre la réflexion sur l’évolution possible du métier face aux rapides changements entraînés par l’avènement du big data et de ses applications (Bamberger, The future of development evaluation in the age of big data 2017a). Concernant la Suisse, la Confédération a publié, fin 2019, le rapport d’un groupe de travail interdépartemental sur la question des défis de l’intelligence artificielle pour les administrations publiques (SEFRI 2019).
2.3. L’accalmie du débat depuis 2018
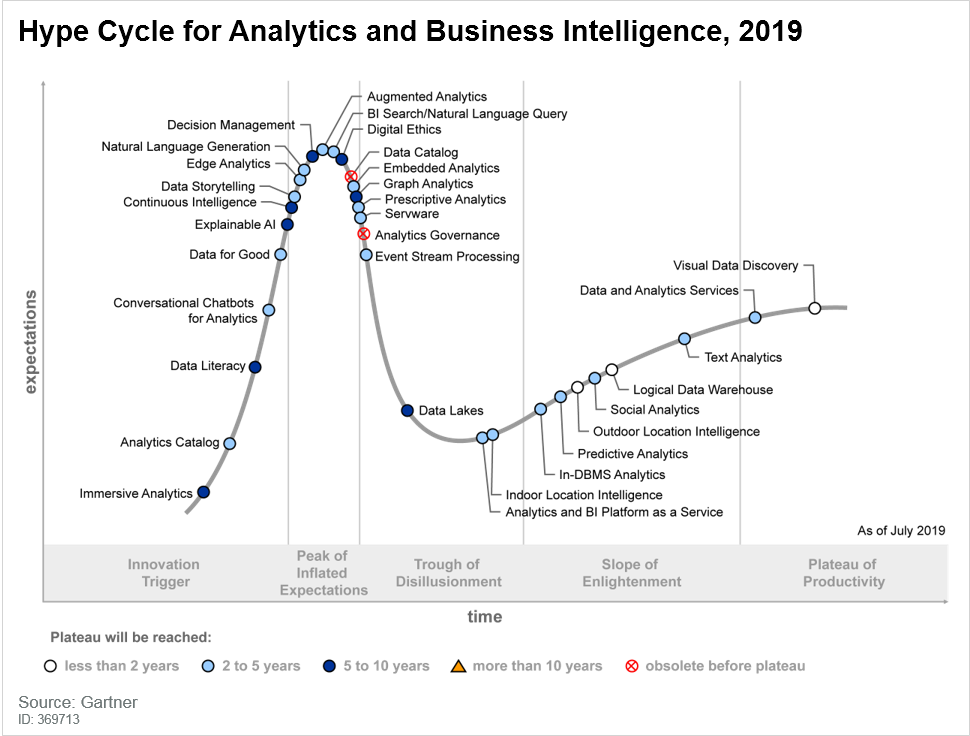
Vu depuis mi- 2020, la discussion scientifique semble s’estomper à partir de 2018. Il apparaît que l’enthousiasme pour le big data subit le contre-coup de l’effet de nouveauté, comme décrit par la courbe de Gartner. Néanmoins, selon ce même modèle, il est attendu que l’attention remonte progressivement, une fois que les technologies auront atteint un certain degré de maturation.
Quantités annuelles d’articles tagués « big data » sur merltech.org et betterevaluation.org

« Hype cycle » de Gartner
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie