
La data science au service des administrations
3. Quelques définitions
3.1. Le machine learning
Le machine learning (ou apprentissage automatique) est le « processus par lequel un algorithme évalue et améliore ses performances sans l’intervention d’un programmeur, en répétant son exécution sur des jeux de données jusqu’à obtenir, de manière régulière, des résultats pertinents » (République française 2018). Malgré quelques développements précoces depuis les années 1950, la recherche dans le domaine ne s’est intensifiée qu’à partir du 21e siècle, grâce à l’explosion des puissances de calcul et du big data (Foote 2020). Le machine learning distingue deux types majeurs d’apprentissage (Shalev-Shwartz et Ben-David 2014, 22-23) :
- L’apprentissage supervisé – la machine fournit des prédictions sur la base de données labellisées (par exemple, le prix d’une maison en fonction de ses caractéristiques ou la réussite scolaire d’un étudiant en fonction de son profil).
- L’apprentissage non-supervisé – la machine fournit des prédictions qui n’ont pas été renseignées préalablement (par exemple, en détectant des données anormales ou en regroupant les données par fonction de similarité).
Typiquement, le machine learning trouve son utilité pour effectuer des tâches trop complexes à programmer (Shalev-Shwartz et Ben-David 2014, 21-22). Il vise particulièrement :
- Les tâches qu’un être humain ou un animal peut effectuer de façon routinière (e. g. la détection d’objet et la conduite automatique).
- Les tâches comprenant un si grand nombre de paramètres que leur appréhension dépasse les capacités humaines (e. g. les prévision météo).
- Les tâches qui demandent une grande adaptation à de nouveaux paramètres (e. g. la reconnaissance de textes manuscrits).
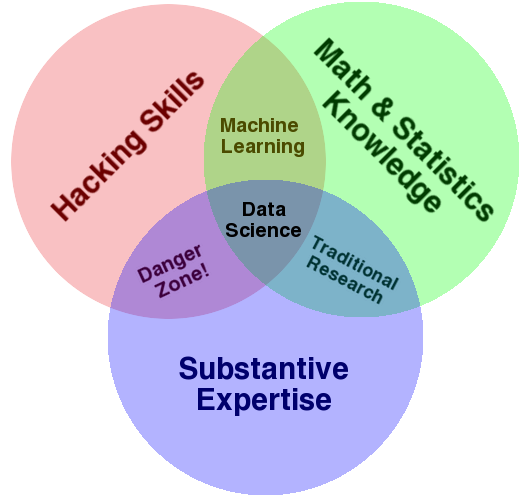
3.2. La data science (ou science des données)
« Data science is a multifaceted discipline, which encompasses machine learning and other analytic processes, statistics and related branches of mathematics, increasingly borrows from high performance scientific computing, all in order to ultimately extract insight from data and use this new-found information to tell stories. »
(Mayo 2017)
Le machine learning est également une discipline à la frontière des sciences mathématiques et informatiques, plus récemment attribuée au domaine plus large de la data science. Si la data science ne trouve pas encore de définition universelle, elle reste le plus souvent vue comme un domaine d’étude interdisciplinaire.
Diagramme de Venn de la data science
3.3. Le big data
Comme le machine learning, la data science doit son expansion à l’avènement du big data. Le big data marque une rupture avec les données qui le précèdent, non seulement par son volume remarquable, mais aussi par le défi qu’il pose aux méthodes traditionnelles de traitement des données.
Le big data est un « ensemble d’une très grande quantité de données, structurées ou non, se présentant sous différents formats et en provenance de sources multiples, qui sont collectées, stockées, traitées et analysées dans de courts délais, et qui sont impossibles à gérer avec des outils classiques de gestion de bases de données ou de gestion de l’information. »
(Office québécois de la langue française 2020)
En évaluation du développement, l’UN Global Pulse (2016, 34-38) précise que le big data ne se résume pas seulement à la génération de données massives : il comporte également l’écosystème des acteurs autour des données ainsi que de la façon dont ces dernières sont mises en forme et en valeur.
Les trois dimensions du big data

3.4. L’évaluation
Dans l’usage courant, l’évaluation désigne l’opération par laquelle on juge la valeur d’une chose (CNRTL 2012). Néanmoins, les spécialistes du domaine s’accordent sur une définition plus précise :
« Evaluation is the systematic assessment of the design, implementation or results of an initiative for the purposes of learning or decision-making. »
(CES 2016)
L’évaluation est par définition liée à la gestion de projet, de programme ou de politique publique (par métonymie, le terme désigne aussi la discipline consacrée à son étude). Elle s’attache principalement à produire des connaissances utiles au moyen d’une méthodologie rigoureuse. La question des buts de l’évaluation reste toutefois ouverte selon les différents courants de pensée qui l’abordent. Ces courants révèlent trois paradigmes principaux sur le but premier de l’évaluation :
- L’évaluation comme outil d’aide à la décision (Campbell 1969) : elle mesure la valeur d’une nouvelle réforme sur la base d’expérimentations contrôlées.
- L’évaluation comme outil de production de savoir (Scriven 1991) : elle produit des connaissances sur les effets du projet, indépendamment des objectifs de ce dernier.
- L’évaluation comme outil d’amélioration (Patton 2008) : elle guide continuellement le projet en fonction des besoins de ses destinataires.
Arbre des théories en évaluation
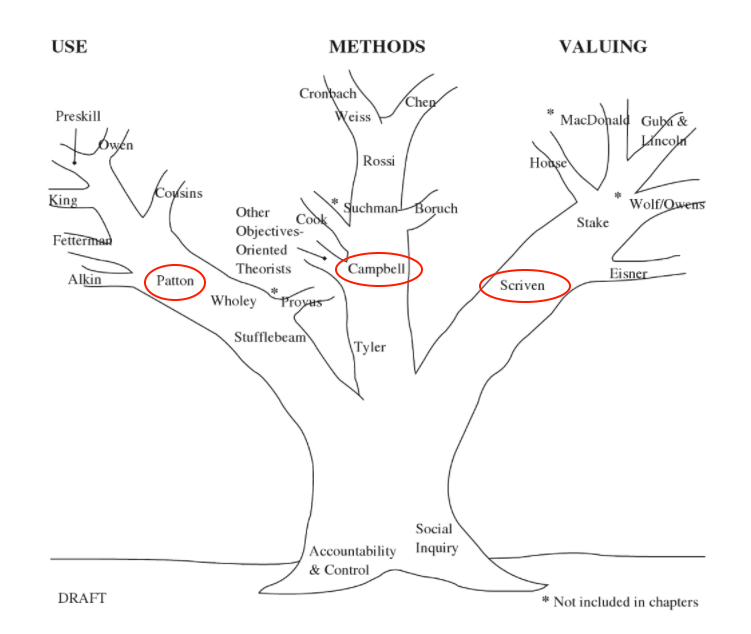
Les nouvelles méthodes de récolte et d’analyse apportées par la data science s’appliquent particulièrement bien à l’amélioration continue du projet (approche de Patton), en raison de l’immédiateté du big data et de la possibilité d’un monitoring en temps réel.
Utilisation des données de téléphonie mobile pour mesurer les déplacements de populations


Des projets en data science peuvent également être réalisés ex-post (approche de Campbell), typiquement pour enrichir une étude qui inclut différents outils d’analyse. Enfin, en pratique, l’application du big data permet également la découverte d’informations inédites et indépendantes des objectifs du mandat (approche de Scriven). En effet, les masses de données à disposition ne sont généralement pas récoltées dans un but particulier et peuvent renfermer des informations inattendues.
Considérer l’évaluation comme un outil d’amélioration de projets, de programmes ou de politiques publiques s’insère dans les perspectives théoriques étayées sur le sujet. Dès lors, il est raisonnable de considérer le machine learning (et, plus largement, la data science) comme un instrument d’analyse opportun, voire parfois incontournable pour tirer profit du big data, pour lequel les méthodes traditionnelles sont inadaptées.
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie