
La data science au service des administrations
6. La gestion des tickets d’incident
En délivrant des services informatisés (e-démarches, poursuites, etc.), l’administration assume également la gestion des problèmes des usagers. Comme pour beaucoup de supports techniques, les problèmes se ressemblent et les équipes passent un temps important à répéter les mêmes instructions. Une façon de résoudre ce problème est de créer une foire aux questions (FAQ) à disposition des usagers. Néanmoins, ces derniers préfèrent le plus souvent ouvrir un ticket, imposant un temps d’attente ainsi qu’une charge de travail pour l’équipe de support. Une solution plus ambitieuse est d’automatiser l’analyse de tickets pour trouver des contenus similaires et rediriger immédiatement l’utilisateur vers une réponse appropriée. Une telle application contribue grandement à l’expérience des usagers, tout en déchargeant l’administration qui reçoit une centaine de milliers de tickets par année.
L’algorithme présenté ici utilise les données publiées par Quora, un site web qui met en relation des utilisateurs et leurs questions avec des experts du domaine concerné :
« Over 100 million people visit Quora every month, so it’s no surprise that many people ask similarly worded questions. Multiple questions with the same intent can cause seekers to spend more time finding the best answer to their question, and make writers feel they need to answer multiple versions of the same question. Quora values canonical questions because they provide a better experience to active seekers and writers, and offer more value to both of these groups in the long term. »
(Quora 2017)
Exemple de suggestions de questions similaires sur quora.com
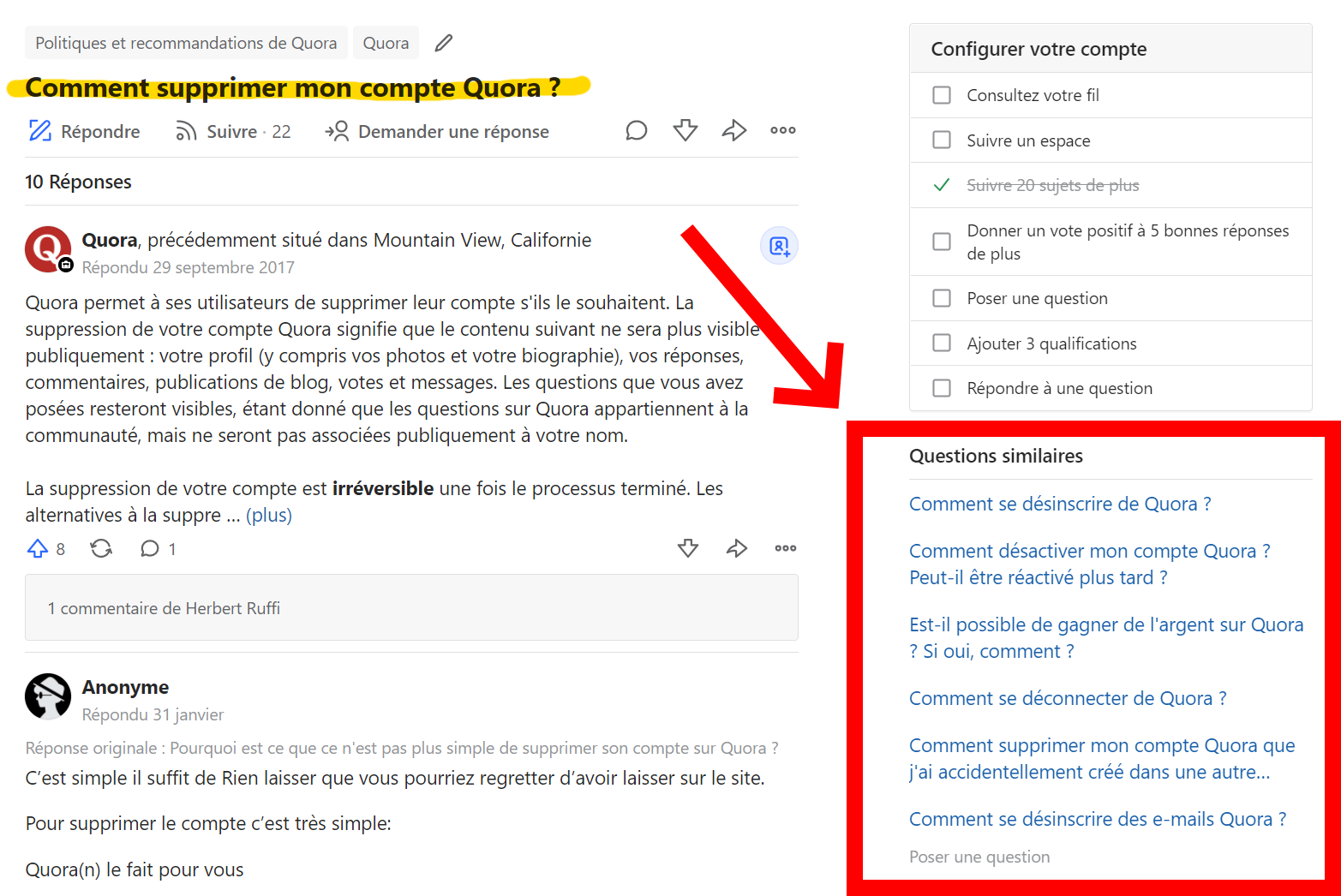
En data science, le traitement du langage naturel est un problème complexe et les solutions les plus efficaces demandent généralement une préparation minutieuse des données, ainsi que plusieurs modèles successifs qui sont, pour certains, préalablement entraînés. Pour des raisons didactiques, la solution présentée ici se limite à quelques opérations.
6.1. Algorithme de prédiction des questions similaires
6.1.1. Importation des librairies et des données
Le jeu de données de Quora compte 404’209 paires de questions labellisées comme des doublons (36,92 %) ou des questions différentes (63,08 %). Les paires de questions rassemblent 537’361 textes distincts.
Colonnes du jeu de données
- id – l’indice de la paire de questions
- qid1 – l’indice de la première question de la paire
- qid2 – l’indice de la seconde question de la paire
- question – la première question de la paire
- question2 – la seconde question de la paire
- is_duplicate – si les deux questions sont des doublons (1) ou non (0)
# ==========================
# Importation des librairies
# ==========================
# Traitement des données
import numpy as np
import pandas as pd
# Natural Language Processing
import spacy
# Machine Learning
from xgboost import XGBClassifier
from sklearn.metrics import classification_report, roc_curve, \
roc_auc_score, plot_confusion_matrix
# Visualisation
import matplotlib.pyplot as plt
import seaborn as sns
# =======================
# Importation des données
# =======================
# Lit le fichier
df = pd.read_csv('train.csv') Exemple de quelques lignes et colonnes du jeu de données

Exemple d’une paire de doublons :
- Do you believe there is life after death?
- Is it true that there is life after death?
Exemple d’une paire de questions différentes :
- What is the step by step guide to invest in share market in india?
- What is the step by step guide to invest in share market?
6.1.2. Nettoyage des données
Pour l’entraînement, seuls les textes (‘question1’ et ‘question2’) et les labels (‘is_duplicate’) sont retenus. De plus, les lignes comportant des données manquantes sont supprimées.
# =====================
# Nettoyage des données
# =====================
# Sélectionne les données
df = df[['question1', 'question2', 'is_duplicate']]
# Supprime les données manquantes
df.dropna(inplace=True) 6.1.3. Préparation des données
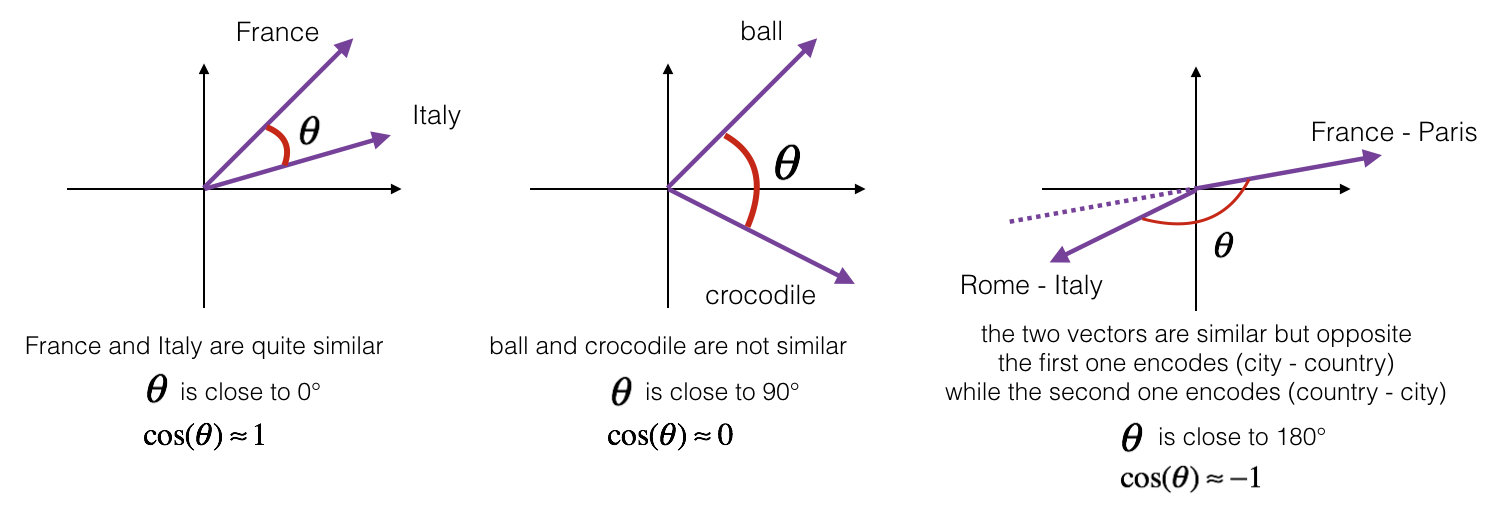
Une invention majeure des dernières années en traitement du langage naturel fut le plongement lexical (word embedding en anglais), notamment grâce au développement du groupe de modèles appelés Word2Vec (Mikolov, et al. 2013). Le plongement lexical consiste à transformer les mots d’un texte en valeurs numériques (vecteurs). Le résultat rend ainsi possible les opérations mathématiques et, par extension, les analogies : par exemple, le modèle est non seulement capable de différencier « homme » et « femme », mais il comprend également qu’ils entretiennent une relation similaire aux mots « roi » et « reine ».
Représentation visuelle simplifiée de vecteurs de mots traités par plongement lexical
Pour cet exercice, les questions sont vectorisées en utilisant la librairie spaCy qui offre des modèles pré-entraînés sur plusieurs millions de textes. Chaque question est ainsi décomposée en ensemble de vecteurs de mots, dont la moyenne représente la question entière sur 300 dimensions. Par simplicité, les questions vectorisées sont uniquement jointes en un nouveau vecteur de 600 dimensions. Comme il s’agit d’un entraînement supervisé, les questions vectorisées (les prédicteurs) sont séparées des labels (à prédire). Les lignes pour l’entraînement (90 %) sont également séparées des lignes pour l’évaluation du modèle (10 %).
# =======================
# Préparation des données
# =======================
# Importe le modèle entraîné pour le traitement du langage naturel
nlp = spacy.load('en_core_web_md')
# Transforme les questions de chaque colonne en vecteurs
q1 = [doc for doc in nlp.pipe(df['question1'])]
q2 = [doc for doc in nlp.pipe(df['question2'])]
# Définit les prédicteurs et les valeurs à prédire
X = np.array([np.hstack((doc1.vector, doc2.vector))
for doc1, doc2 in zip(q1, q2)])
y = df['is_duplicate'].values.reshape(-1, 1)
# Sépare le jeu d'entraînement du jeu de données
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.1) Quelques valeurs d’un vecteur de 300 dimensions représentant une question

6.1.4. Modélisation
Le modèle choisi pour l’entraînement est le classificateur XGBoost (Extreme Gradient Boosting). Le XGBoost est un algorithme de machine learning basé sur un ensemble d’arbres de décision et dont la performance a fait la renommée dans beaucoup d’applications (Chen et Guestrin 2016). L’apprentissage est paramétrable de plusieurs manières et cette étape requiert typiquement plusieurs itérations qui ne seront pas démontrées ici par souci de concision.
# ============
# Modélisation
# ============
# Entraînement du modèle
clf = XGBClassifier(n_estimators=100,
max_depth=10,
learning_rate=1,
objective='binary:logistic',
n_jobs=-1,
random_state=0,
reg_lambda=20)
eval_set = [(X_train, y_train), (X_test, y_test)]
clf.fit(X_train, y_train,
eval_set=eval_set,
eval_metric='auc',
verbose=True)
# Dessine l'évolution de l'AUC au fil des itérations
fig, ax = plt.subplots()
x = range(clf.get_params()['n_estimators'])
results = clf.evals_result()
ax.plot(x, results['validation_0']['auc'], label='Train')
ax.plot(x, results['validation_1']['auc'], label='Test')
ax.legend()
plt.xlabel('epochs')
plt.ylabel('AUC')
plt.title('XGBoost AUC'); Après 100 itérations de calcul, le modèle obtient un AUC1L’aire sous la courbe ROC (AUC) tient compte des taux de vrais positifs et des faux positifs (Narkhede 2018). L’AUC est particulièrement adaptée pour mesurer la performance des prédictions lorsque la distribution de classes est déséquilibrée. final de 0.87 (sur 1) sur le jeu de test.
# Dessine l'évolution de l'AUC au fil des itérations
fig, ax = plt.subplots()
x = range(clf.get_params()['n_estimators'])
results = clf.evals_result()
ax.plot(x, results['validation_0']['auc'], label='Train')
ax.plot(x, results['validation_1']['auc'], label='Test')
ax.legend()
plt.xlabel('epochs')
plt.ylabel('AUC')
plt.title('XGBoost AUC'); Évolution des performances du modèle au fil de l’apprentissage

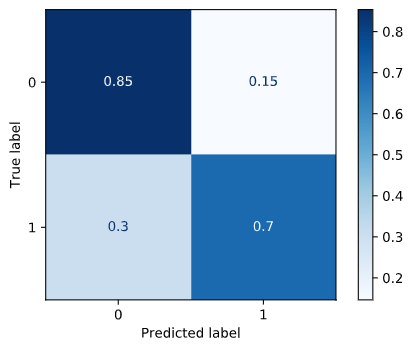
La matrice de confusion révèle que, si le modèle réussit à prédire correctement 85 % des paires distinctes, il peine davantage à reconnaître les questions dupliquées (70 %). Cette indication est particulièrement utile pour choisir la façon dont les recommandations sont soumises aux internautes. Par exemple, dans le cas de Quora, afficher plusieurs questions rapidement lisibles diminue la gravité d’un faux positif pour l’expérience utilisateur.
# Dessine la matrice de confusion
plot_confusion_matrix(clf, X_test, y_test,
normalize='true',
cmap=plt.cm.Blues); Matrice de confusion des prédictions du classificateur XGBoost
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie