
La data science au service des administrations
4. Prédire les contraventions impayées de la ville Détroit
En 2017, la ville de Detroit a lancé une compétition publique pour l’aider à résoudre son problème de contraventions impayées (Kaggle 2019). Il s’agit plus précisément des blight tickets, des contraventions infligées aux résidents qui manquent de préserver le bon état de leur propriété (détérioration, graffitis, insalubrité, etc.). Malheureusement, la plupart de ces contraventions demeurent impayées à la fin du délai légal, entraînant des procédures administratives lourdes et coûteuses pour les autorités. La ville a donc cherché à accroître le respect du paiement des contraventions (dit aussi compliance). Pour en comprendre les déterminants, une étape visait à identifier les meilleurs prédicteurs de la compliance. La ville a ainsi publié ses données en vue d’obtenir un modèle prédictif performant.
4.1. Algorithme de prédiction des contraventions impayées
4.1.1. Importation des librairies et des données
Le jeu de données destiné à l’entraînement (train) recense 250’306 contraventions, chacune informée de 34 informations différentes (numéro de ticket, lieu, montant, type d’infraction, compliance, etc.). Il compte 11’597 contraventions payées (4,63 %) contre 148’282 contraventions impayées (59,24 %) ; le reste (36,13%) est sans label. Un jeu de données plus petit (test) de 61’001 contraventions sert à l’évaluation du modèle : le résultat à prédire (la compliance) est volontairement amputé. Les compétiteurs envoient leurs prédictions et la ville leur rend un score de performance. Quatre fichiers de données sont fournis :
- train.csv – les données d’entraînement
- test.csv – les données de test
- addresses.csv – les adresses complètes extraites des données d’entraînement
- latlons.csv – la traduction de ces adresses en longitude et latitudes
# ==========================
# Importation des librairies
# ==========================
# Traitement des données
import pandas as pd
import numpy as np
# Machine learning (modèle prédictif)
from sklearn.ensemble import RandomForestClassifier# =======================
# Importation des données
# =======================
# Lit les fichiers de données
train = pd.read_csv('train.csv', encoding='ISO-8859-1')
test = pd.read_csv('test.csv', encoding='ISO-8859-1')
addresses = pd.read_csv('addresses.csv')
latlons = pd.read_csv('latlons.csv')Quelques lignes et colonnes de données publiées sur l’Open Data Portal de Détroit (2020)
4.1.2. Nettoyage des données
Le nettoyage des données consiste en deux étapes :
- L’ajout de nouvelles informations aux données d’entraînement qui pourraient être utiles à l’apprentissage : la longitude et la latitude des adresses des infractions.
- La sélection des colonnes pertinentes1La sélection des colonnes est généralement renforcée par le résultat d’une analyse exploratoire des données ainsi que de multiples itérations du modèle. Par souci de concision, le choix repose ici sur une première intuition.. Cette opération implique d’adapter le jeu de test en conséquence : les deux jeux doivent comporter les mêmes colonnes, pour que le modèle entraîné sur l’un puisse être appliqué à l’autre. Les colonnes retenues distinguent les prédicteurs de la valeur à prédire.
# =====================
# Nettoyage des données
# =====================
# Complète manuellement quelques longitudes et latitudes manquantes
latlons.loc[4126, ['lat', 'lon']] = [42.376863, -83.143196]
latlons.loc[10466, ['lat', 'lon']] = [42.446764, -83.023189]
latlons.loc[17293, ['lat', 'lon']] = [42.359998, -83.095806]
latlons.loc[34006, ['lat', 'lon']] = [42.358953, -83.151346]
latlons.loc[55750, ['lat', 'lon']] = [42.358784, -83.080457]
# Supprime les contraventions qui contiennent des valeurs manquantes
latlons.drop(latlons[latlons.isnull().any(axis=1)].index, inplace=True)
# Fusionne les adresses avec les longitudes et latitudes
loc = pd.merge(addresses, latlons, on = 'address')
# Définit les colonnes du jeu d’entraînement qui ne sont pas dans le jeu de test
# et les retire du jeu d’entraînement (excepté la colonne "compliance")
cols_not_in_test = [col for col in train.columns
if (col not in test.columns)
and (col != 'compliance')]
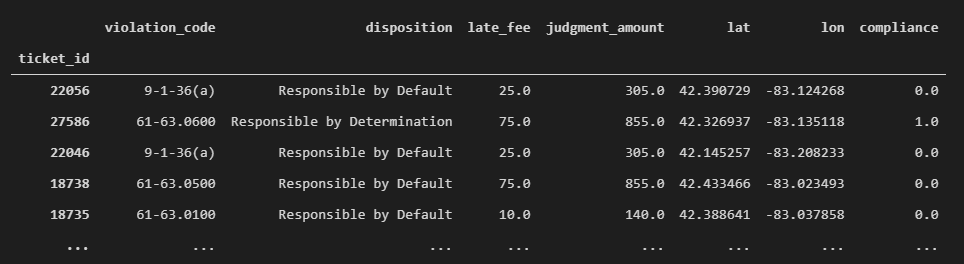
train = train.drop(cols_not_in_test, axis=1)Les prédicteurs sélectionnés
- violation_code – le type d’infraction
- disposition – le type de jugement posé
- late_fee – la taxe de retard de payement
- judgment_amount – le montant de la contravention
- lat – la latitude de l’adresse de l’infraction
- lon – la longitude de l’adresse de l’infraction
La valeur à prédire
- compliance – si la contravention est payée (1) ou non (0). NaN indique une contravention annulée.
Quelques lignes des données d’entraînement
4.1.3. Préparation des données
L’étape consiste à séparer les prédicteurs de la valeur à prédire (la « compliance »), ainsi qu’à encoder les colonnes qui contiennent des chaînes de caractères en valeurs numériques interprétables par une machine.
# =======================
# Préparation des données
# =======================
# Fusionne les longitudes et latitudes avec les jeux d’entraînement et de test
train = pd.merge(train, loc, on='ticket_id')
test = pd.merge(test, loc, on='ticket_id')
# Supprime les lignes où la compliance est une donnée manquante (NaN)
# (i.e. la contravention est annulée)
train = train.dropna(subset=['compliance'])
# Définit les numéros de ticket comme l’index des contraventions
train.set_index('ticket_id', inplace=True)
test.set_index('ticket_id', inplace=True)
# Sélectionne manuellement les colonnes pour l’entraînement
cols_for_training = ['violation_code',
'disposition',
'late_fee',
'judgment_amount',
'compliance',
'lat',
'lon']
train = train[cols_for_training]
# Sélectionne les colonnes du jeu de test pour correspondre au jeu d’entraînement
test = test[[col for col in cols_for_training if col != 'compliance']]
# Supprime les lignes contenant des valeurs manquantes.
train.drop(train[train.isnull().any(axis=1)].index, inplace=True)
# Sépare les prédicteurs de la valeur à prédire ("compliance")
X_train = train.drop('compliance', axis=1)
y_train = train.loc[:, 'compliance']
X_test = test
# Encode les colonnes des chaînes de caractères pour n’obtenir que des valeurs numériques
# (demande de fusionner puis de séparer les jeux d’entraînement et de test)
X = X_train.append(X_test)
cols_to_encode = [col for col in train.columns.values
if np.dtype(train[col].dtype) != 'float64']
X = X.join(pd.get_dummies(X[cols_to_encode])).drop(cols_to_encode, axis=1)
X_train = X.loc[:X_train.index[-1], :]
X_test = X.loc[X_test.index[0]:, :] 4.1.4. Modélisation
Le modèle sélectionné est le classificateur Random Forest, un algorithme construit sur un ensemble d’arbres de décision (Breiman 2001). Par souci didactique, les paramètres par défaut du modèle restent inchangés.
# ============
# Modélisation
# ============
# Entraîne le modèle avec les données du jeu d’entraînement
clf = RandomForestClassifier(random_state=0).fit(X_train, y_train)
# Calcule la probabilité de compliance pour chaque contravention du jeu de test
y_proba = pd.Series(clf.predict_proba(X_test)[:, 1], index=X_test.index)
# Affiche la liste des probabilités prédites
y_proba
# >> ticket_id
# 284932 0.00
# 285362 0.00
# 285361 0.10
# ... Cet algorithme offre un AUC de 0.7552L’aire sous la courbe ROC (AUC) tient compte des taux de vrais positifs et des faux positifs (Narkhede 2018). L’AUC est particulièrement adaptée pour mesurer la performance des prédictions lorsque la distribution de classes est déséquilibrée. (sur 1), soit à la 9e place des 24 compétiteurs de l’époque. Il permet d’identifier des variables prédictives de la compliance des contrevenants. Accompagné d’autres méthodes d’analyse (études de cas, entretiens, tests statistiques, etc.), il offre une meilleure compréhension des déterminants de la compliance des contraventions, tout en informant la probabilité de résultat des cas futurs avec une fiabilité éprouvée.
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie