
La data science au service des administrations
5. La prédiction des pannes (ou maintenance prédictive)
La santé des serveurs informatiques est essentielle à la qualité des prestations publiques, tant pour les habitants (e.g. les services e-démarches) que pour les collaborateurs de l’État (e.g. les logiciels de travail). Dans ce contexte, l’équipe responsable des serveurs est confrontée à deux problèmes : d’une part, les pannes critiques doivent absolument être évitées pour assurer la continuité des services ; d’autre part, multiplier les opérations de maintenance est coûteux et fastidieux pour l’administration, alors que la plupart des machines examinées ne présentent aucun signe de dégradation. Un indicateur fiable de prédiction de pannes apparaît alors comme une solution enviable. Ce problème repose sur deux hypothèses :
- Bien que la rapidité et la linéarité de la dégradation dépendent de l’utilisation et de l’environnement, la santé de la machine diminue dans le temps, jusqu’à tomber en panne.
- L’état d’une machine doit pouvoir être interprétée grâce à plusieurs indicateurs fournis par des sondes (par exemple, la température ou le taux d’utilisation du processeur).
Dans la plupart des cas, les machines disposent par défaut de sondes et une façon classique de gérer les défaillances est de fixer un seuil d’alarme sur une ou plusieurs d’entre elles. À défaut d’utiliser les données confidentielles des serveurs de l’État, l’algorithme utilise des données similaires publiées par la NASA (2008)1Ces données proviennent non pas de serveurs, mais de moteurs aéronautiques. Malgré cela, elles offrent une forme typique de données de sonde machine. et suit le scénario suivant :
L’équipe de maintenance est chargée d’examiner un parc de 100 unités de machines tous les 125 cycles d’utilisation. À chaque examen, l’équipe peut vérifier l’état de dégradation des unités et apporter les réparations nécessaires. Néanmoins, si certaines machines demandent parfois une intervention, les techniciens constatent que l’immense majorité des appareils pourrait encore effectuer plusieurs cycles. Ces examens coûtent cher et il est demandé de trouver un meilleur indicateur pour décider d’envoyer un appareil en maintenance. En dehors des retours des techniciens, aucune information sur les pannes n’est enregistrée à ce jour.
La base de données de la NASA offre des informations sur un large nombre d’unités et de cycles. Afin de correspondre au scénario, seules les informations concernant les 125 premiers cycles des 100 premières unités sont retenues. Comme l’exercice implique la production de plusieurs graphiques, le code est introduit au fil des explications.
5.1. Algorithme de prédiction des pannes
L’algorithme développé ci-après repose en partie sur la présentation de Adam Filion (2016).
5.1.1. Importation des librairies
# ==========================
# Importation des librairies
# ==========================
# Traitement des données
import pandas as pd
import numpy as np
from sklearn.preprocessing import StandardScaler
# Machine Learning
from sklearn.decomposition import PCA
# Visualisation
import matplotlib.pyplot as plt 5.1.2. Importation des données
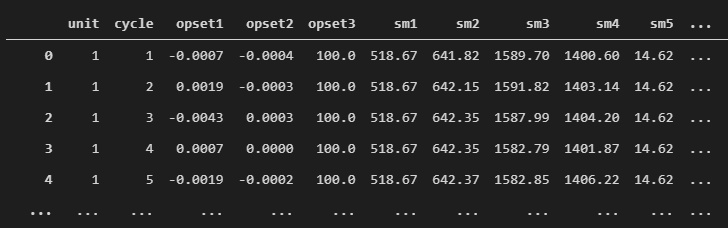
Chaque ligne contient 21 mesures de senseurs. Les noms des colonnes n’étant pas renseignés, un dictionnaire est défini pour compléter les informations à partir de la documentation annexe.
Description des colonnes
- unit – le numéro de la machine
- cycle – le numéro du cycle d’utilisation de la machine
- opset# – les 3 réglages opérationnels de la machine (operational setting)
- sm# – les mesures des 21 sondes de la machine (sensor measurement)
# =======================================
# Définition du dictionnaire des colonnes
# =======================================
cols_dict = {0: 'unit', 1: 'cycle', 2: 'opset1', 3: 'opset2', 4: 'opset3', 5: 'sm1', 6: 'sm2', 7: 'sm3', 8: 'sm4', 9: 'sm5', 10: 'sm6', 11: 'sm7', 12: 'sm8', 13: 'sm9', 14: 'sm10', 15: 'sm11', 16: 'sm12', 17: 'sm13', 18: 'sm14', 19: 'sm15', 20: 'sm16', 21: 'sm17', 22: 'sm18', 23: 'sm19', 24: 'sm20', 25: 'sm21'}
# =======================
# Importation des données
# =======================
# Lit le fichier des 100 unités
df = pd.read_csv(data_folder / 'train_FD001.txt', sep=' ', header=None) \
.drop([26,27], axis=1)
# Sélectionne les données jusqu'au cycle 125
df = df.query('cycle <= 125') Quelques lignes et colonnes du jeu de données
5.1.3. Nettoyage des données
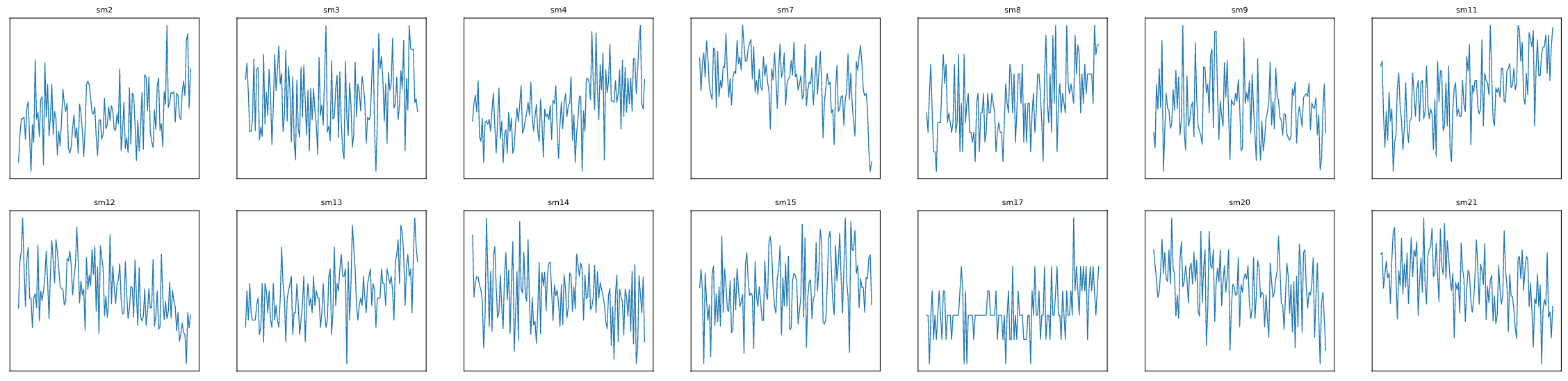
Seules les informations sur l’unité (unit), le cycle (cycle) et les mesures des sondes (sm#) sont retenues. Une première exploration révèle que certaines sondes fournissent des mesures avec un écart-type inférieur à 0.01. Les mesures constantes n’apportent aucune information sur l’évolution de la machine dans le temps et sont donc exclues des analyses.
# =====================
# Nettoyage des données
# =====================
# Sélectionne les colonnes qui ont un écart-type proche de zéro
std = df.describe().loc["std", :]
cols_to_del = std.loc[std < 0.01].index.tolist()
# Supprime les colonnes presque constantes
df.drop(cols_to_del, axis=1, inplace=True)Exemple des mesures des sondes pour une unité (125 cycles)
5.1.4. Préparation des données
La préparation des données est une étape importante pour faciliter l’apprentissage d’un modèle de machine learning. La documentation de la NASA indique que les données sont contaminées par du bruit et les mesures représentent différentes métriques et échelles. Par conséquent, il est raisonnable d’atténuer le bruit des senseurs et de standardiser les mesures (afin d’obtenir une moyenne de 0 et une variance de 1 pour chaque senseur).
# =======================
# Préparation des données
# =======================
# Réduit le bruit des senseurs par moyenne glissante (trailing moving average)
sensors = [sensor for sensor in df.columns
if sensor.startswith('sm')]
df.set_index('cycle', inplace=True)
df = df.groupby('unit')[sensors] \
.rolling(window=3, min_periods=1).mean() \
.reset_index(level=['unit', 'cycle'])
# Standardise les données des senseurs
scaler = StandardScaler()
df[sensors] = scaler.fit_transform(df[sensors]) Les mesures précédentes après réduction du bruit et standardisation

5.1.5. L’analyse par composantes principales (PCA)
Comme les informations sur les pannes ne sont pas disponibles, le modèle de machine learning repose sur un apprentissage non-supervisé par l’analyse par composantes principales, ou principal component analysis (PCA). La PCA est une méthode par laquelle la dimensionnalité des données est réduite par projection sur un plan moins complexe (Tipping et Bishop 1999). Elle est souvent utilisée dans le traitement d’images, grâce à l’allègement qu’elle confère aux flux de données (comme le streaming ou la reconnaissance faciale par exemple).
Exemple de décomposition de photos de visages par PCA

La PCA est également employée pour représenter des données graphiquement (e.g. sur un plan à deux dimensions). Néanmoins, si les données sont simplifiées, il est important de savoir à quel point elles représentent les données initiales. Pour cela, le pourcentage de covariance expliquée est usuellement un bon indicateur. Ainsi, pour représenter les données des machines sur un graphique à deux dimensions, les deux premières composantes principales, expliquant ensemble 81 % de la variance des données initiales, sont retenues.
# ===================================
# Analyse par composantes principales
# ===================================
# Entraîne le modèle et transforme les données
pca = PCA(n_components=2)
df_pcs = pca.fit_transform(df[sensors])
# Dessine le graphique
plt.scatter(df_pcs[:, 0], df_pcs[:, 1],
marker='.', s=2, alpha=0.8)
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2'); Les données après réduction par PCA

Représentation graphique des composantes principales
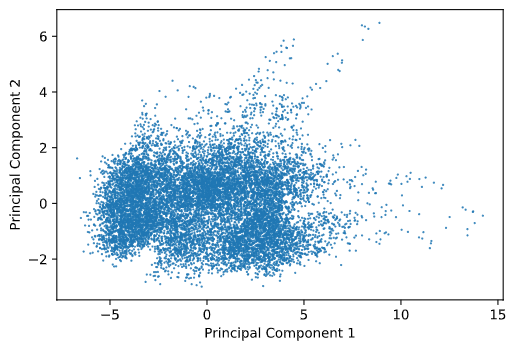
Le graphique révèle deux informations : 1) la plupart des données sont groupées dans une certaine zone ; 2) il y a des données qui s’écartent de la masse (vers la droite et le haut droit). Une hypothèse serait que les données tendent à s’écarter du centre au fil des utilisations et, par conséquent, afficher un déplacement entre le début et la fin de vie des appareils. Pour tester cette hypothèse, les premiers et derniers cycles (les 125e) de chaque unité sont mis en évidence, ainsi que leurs centres de masse respectifs.
# ============================================================
# Les appareils s'écartent-t-ils du centre au fil des cycles ?
# ============================================================
# Sélectionne les premiers et derniers cycles de chaque unité
first_cycles = df.groupby('unit').first().reset_index()[sensors]
last_cycles = df.groupby('unit').last().reset_index()[sensors]
# Transforme les données
first_cycles_pcs = pca.transform(first_cycles)
last_cycles_pcs = pca.transform(last_cycles)
# Calcule le point central des premiers puis des derniers cycles
fist_cycles_pcs_centroid = first_cycles_pcs.mean(axis=0)
last_cycles_pcs_centroid = last_cycles_pcs.mean(axis=0)
# Dessine le graphique
plt.scatter(df_pcs[:, 0], df_pcs[:, 1], marker='.', s=2, alpha=0.8)
plt.scatter(first_cycles_pcs[:, 0], first_cycles_pcs[:, 1],
c='black', marker='.', s=10, alpha=0.8, label='First cycles')
plt.scatter(fist_cycles_pcs_centroid[0], fist_cycles_pcs_centroid[1],
c='lime', marker='o', label='First cycles centroid')
plt.scatter(last_cycles_pcs[:, 0], last_cycles_pcs[:, 1],
c='r', marker='.', s=10, alpha=0.8, label='Last cycles')
plt.scatter(last_cycles_pcs_centroid[0], last_cycles_pcs_centroid[1],
c='lime', marker='v', label='Last cycles centroid')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend();Représentation graphique des composantes principales
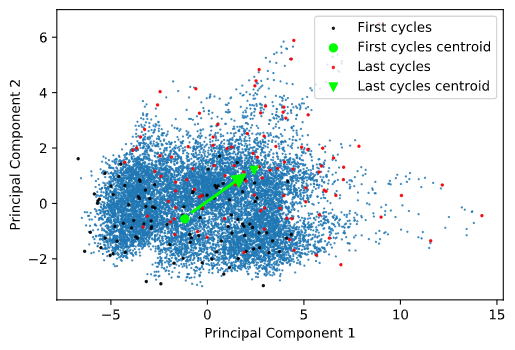
La tendance semble se confirmer et la voie mérite d’être explorée. Dans notre scénario, les techniciens rapportent après maintenance que 4 unités (no. 39, 57, 70 et 91) ont présenté des signes clairs de dégradation durant l’examen. Cette information est très utile, parce qu’elle apporte des cas de dégradation avérés. L’hypothèse peut ainsi à nouveau être testée, en observant cette fois l’évolution des unités en question.
# =============================================================================
# Où se trouvent les 20 derniers cycles des unités particulièrement dégradées ?
# =============================================================================
# Sélectionne les 20 derniers cycles des unités particulièrement dégradées
degraded_units = df[df['unit'].isin([39,57,70,91])]
degraded_units_last_20_cycles \
= degraded_units.groupby('unit').tail(20).reset_index()[sensors]
# Transforme les données
degraded_units_last_20_cycles_pcs = pca.transform(degraded_units_last_20_cycles)
# Dessine le graphique
plt.scatter(df_pcs[:, 0], df_pcs[:, 1], marker='.', s=2, alpha=0.8)
plt.scatter(degraded_units_last_20_cycles_pcs[:, 0],
degraded_units_last_20_cycles_pcs[:, 1],
c='orange', marker='.', s=10, alpha=0.8,
label='Degraded units (last 20 cycles)')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(); Évolution des unités particulièrement dégradées

Les résultats tendent à valider fortement l’hypothèse initiale. Il est ainsi possible de construire un indice de santé selon la position des enregistrements sur le graphique. L’indice de santé comprend trois catégories (normal, warning ou critical) et repose sur des seuils fixes. Il devient alors le nouveau critère de décision de maintenance des appareils.
# ===============================================
# Création de l’indicateur de santé des appareils
# ===============================================
# Attribue à chaque point un indicateur de santé en fonction
# de seuils choisis (0: 'normal', 1: 'warning', 2: 'critical')
health = np.array([((x, y), 0) if (-6.5 < x < 5) & (-3 < y < 2)
else ((x, y), 1) if (-7 < x < 10) & (-4 < y < 5)
else ((x, y), 2)
for x, y in df_pcs])
# Sélectionne les données de chaque indicateur de santé
normal = np.array([(x, y) for ((x, y), state) in health if state == 0])
warning = np.array([(x, y) for ((x, y), state) in health if state == 1])
critical = np.array([(x, y) for ((x, y), state) in health if state == 2])
# Dessine le graphique
plt.scatter(normal[:, 0], normal[:, 1],
c='g', marker='.', s=2, alpha=0.8, label='Normal')
plt.scatter(warning[:, 0], warning[:, 1],
c='y', marker='.', s=2, alpha=0.8, label='Warning')
plt.scatter(critical[:, 0], critical[:, 1],
c='r', marker='.', s=2, alpha=0.8, label='Critical')
plt.xlabel('Principal Component 1')
plt.ylabel('Principal Component 2')
plt.legend(); Représentation graphique des indices de santé

En envoyant un appareil en maintenance au premier warning plutôt qu’au 125e cycle, 41 unités (sur 100) sont épargnées d’une maintenance inutile au 125e cycle2Considérant que la NASA a sélectionné des données proches des pannes réelles, ces résultats sont probablement supérieurs à ce qui peut être obtenu sur des données sans présélection. Néanmoins, pour une administration qui compte des milliers de serveurs dans son parc informatique, un gain même faible d’efficience peut représenter des économies substantielles.. L’avantage notable de ce nouvel indicateur est la prise en compte de la particularité des unités, alors que le critère précédent les évaluait de façon indifférenciée.
Une administration peut s’inspirer du cas de la NASA pour développer un indicateur de santé fiable des serveurs et ainsi éviter des maintenances inutiles. Néanmoins, le cas de la NASA peut demander des ajustements avant de s’appliquer ailleurs, en raison non seulement des machines différentes, mais également du critère initial d’intervention. Par exemple, pour des infrastructures dont les pannes ne sont pas dramatiques (comme des serveurs informatiques), l’équipe de maintenance examine les machines surtout lorsqu’un usager signale des problèmes d’application. Dans ce contexte, la solution serait de fournir l’indicateur de santé directement aux usagers, qui sauraient d’un coup d’œil si leur problème provient de l’infrastructure avant de contacter l’équipe de maintenance.
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi

Les chapitres de ce travail
- Introduction : l’avènement de la data science grâce à la révolution numérique
- Survol de la discussion scientifique
- Quelques définitions
- Prédire les contraventions impayées de la ville Détroit
- La prédiction des pannes (ou maintenance prédictive)
- La gestion des tickets d’incident
- La détection de prestations erronées
- Conclusion
- Bibliographie