
3. Le machine learning au service de l’évaluation
Dans la partie précédente, nous avons présenté les résultats des données récoltées, i.e. les profils et les retours des répondants. Dans cette partie, nous utiliserons le machine learning (ou apprentissage automatique) pour automatiser l’analyse des commentaires.
Les chapitres de cet article
Mon intérêt particulier pour le numérique
Du fait de mon penchant pour les nouvelles technologies et de mon expérience en tant que consultant, je vois dans la data science, le big data et le machine learning une opportunité à ma mission. Force est de constater que le recours à l’intelligence artificielle reste peu répandu en évaluation, pour diverses raisons que Michael Bamberger étaye mieux que moi. Actif au GREVAL depuis sa création, j’ai à cœur de promouvoir l’utilité du numérique pour la gestion de projet et de tisser des liens entre la science des données et l’évaluation.

3.1 L’analyse des sentiments (via Google Cloud)
Humainement, l’analyse de données non-structurées (comme les textes libres) est une tâche chronophage et devient pratiquement irréalisable passé une certaine échelle. Il est cependant aujourd’hui possible d’utiliser des modèles de machine learning pour, entre autres, déterminer le sentiment général d’un texte.
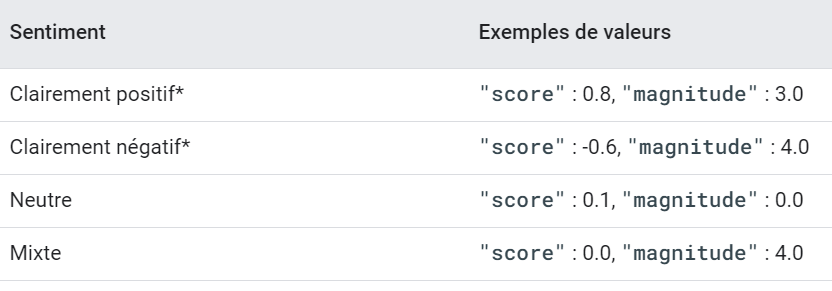
Pour analyser les commentaires des répondants, nous avons utilisé les algorithmes proposés par Google Cloud. Ceux-ci allègent considérablement le travail, en offrant notamment des modèles pré-entraînés adaptés automatiquement à la langue des textes. L’analyse des sentiments retourne, pour chaque texte, deux valeurs :
- le score : l’émotion globale du texte, allant de – 1 (négative) à +1 (positive).
- la magnitude : la quantité de contenu émotionnel présente dans le texte (de 0 à +∞), souvent proportionnelle à la longueur du document.
Comme nous nous intéressons à ce qui a été dit de positif et de négatif sur le congrès, nous décomposons les commentaires les plus longs en phrases. Nous obtenons ainsi 73 textes sur lesquels appliquer notre modèle.
Exemple d’interprétation des scores et magnitudes

À partir des valeurs obtenues, il est possible de représenter visuellement les avis des répondants sur le congrès. Avec un peu d’ingénierie, nous ajoutons de l’interactivité aux données pour naviguer entre les activités (par les onglets), ainsi que pour accéder au texte lié à chaque point (en passant la souris dessus).
Une telle représentation est particulièrement utile pour un décideur confronté à un grand nombre de commentaires et qui désire un aperçu rapide des avis, ou bien qui cherche une solution économique pour écrémer les commentaires et ne retenir que les plus positifs ou négatifs.
Les commentaires sur les conférences, les ateliers et le congrès en général
Notes sur l’utilisation
- Cliquez sur les onglets pour naviguer entre les parties du congrès.
- Utilisez la molette de la souris pour zoomer/dézoomer.
- Cliquez sur le bouton 🔄 sur la droite du graphique pour réinitialiser l’affichage.
- Si vous rencontrez des problèmes pour afficher le graphique, essayez de le charger dans une nouvelle page.
Commentaires sur le graphique
- La préparation des données étant relativement simple, certaines coupures de commentaire ne sont pas forcément pertinentes.
- La magnitude étant une agrégation des composantes du texte, la distribution en « < » est un résultat attendu.
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi
⬤ Vous êtes ici