
1. Un dispositif d’évaluation innovant
Si vous suivez le GREVAL depuis un certain temps, il est probable que nous nous soyons rencontrés au Congrès SEVAL GREVAL du 4 septembre 2020. Comme chaque année, les participants ont été invités à donner leur avis sur le congrès, ainsi que quelques informations sur leur profil. La participation au congrès est payante et il est dès lors précieux pour l’organisateur de disposer de données utiles à l’amélioration de ses événements futurs.
❝ Ce cas illustre plusieurs applications de la Data Science en évaluation ❞
Les chapitres de cet article
Malgré les limites du travail bénévole, nous avons réussi à mettre en place un système moderne et innovant de récolte de données. Ce cas illustre également différentes applications de la Data Science (ou science des données) dans les pratiques évaluatives et, parmi elles, l’intelligence artificielle.



1.1 Une évaluation en continu
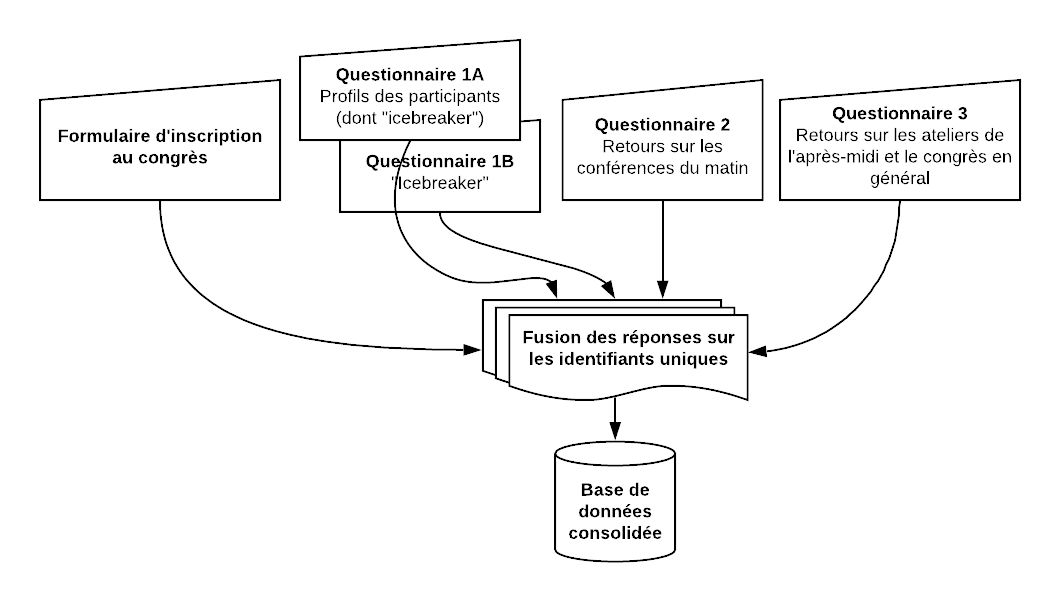
Le GREVAL étant le co-organisateur du congrès, nous avons favorisé un dispositif continu de récolte des données. Malgré un flux de réponses plus complexe, un tel dispositif présente plusieurs avantages :
- Il allège l’intensité de l’investissement – l’idée étant que les gens sont généralement plus disposés à répondre à 5 questionnaires de 3 minutes, espacés dans le temps, plutôt qu’à un questionnaire de 15 minutes.
- Il enregistre incrémentalement les réponses – si les interrogés ne répondent pas à tous les questionnaires, les réponses déjà transmises sont sauvegardées.
- Il profite des moments de haute disponibilité des interrogés – il est par exemple plus facile de récolter des informations au moment de l’inscription en ligne.

Les questionnaires ont été soumis à différents moments, chacun récoltant des informations spécifiques :
- Au moment de l’inscription en ligne – leurs coordonnées, leur langue, etc.
- Le matin du congrès – leur profil, leur avis sur la participation et les motivations de leur venue. Par contraintes techniques et comme nous souhaitions qu’ils répondent aux questions icebreaker durant la session, il a fallu organiser un questionnaire parallèle.
- À midi – leur avis sur les conférences du matin.
- Après la fin du congrès – leur avis sur les ateliers de l’après-midi.
1.2 Privilégier l’expérience utilisateur
Rares sont les personnes qui cultivent une passion pour les questionnaires. Prévenir les refus ou les abandons est une partie importante de la planification de la récolte de données. Grossièrement, il s’agit d’augmenter la disposition des sondés à offrir leur temps à nos questions. Plusieurs stratégies sont possibles : on peut par exemple limiter le nombre de questions, profiter des moments où les coûts d’opportunité sont faibles, recourir à des motivations tierces, etc.
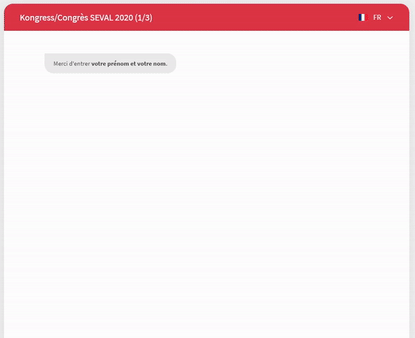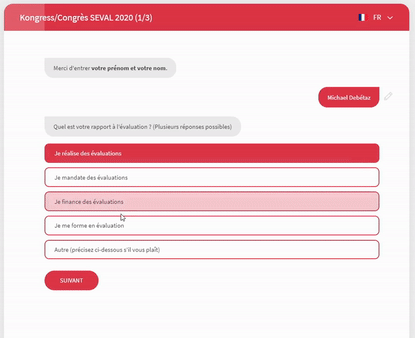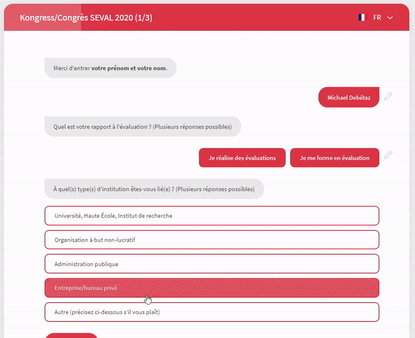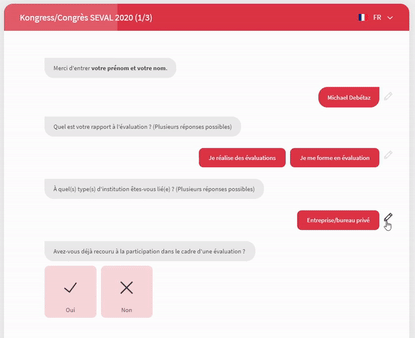
Outre la dilution des questions dans le temps, nous avons recouru à des formulaires de type « conversationnel » (en l’occurrence, la solution Survey Sparrow). Les questions sont soumises sous forme de conversation WhatsApp et le logiciel enregistre les réponses une à une (et non pas à la toute fin du questionnaire).
1.3 Les lacunes du dispositif
Il est important de préciser que le dispositif a été réalisé bénévolement, alors que le temps limité des organisateurs était occupé par des activités prioritaires (la gestion des intervenants, les mesures sanitaires ou la logistique par exemple). Les questionnaires résultent donc du temps qui leur a été consacré. De même, certaines informations n’ont pas été systématiquement recueillies, notamment le nombre effectif de participants. Il n’est pas non plus possible de savoir combien d’inscrits ne sont pas venus, combien de non-inscrits sont venus, ou encore combien sont partis au cours de la journée. Néanmoins, ayant compté approximativement le nombre de personnes dans l’auditoire en matinée, j’estime la population du congrès à environ 100.

2. Les résultats : ~100 participants, 64 répondants
Comme nous nous intéressons avant tout aux retours des participants, nous ne retenons que les 64 personnes qui ont répondu à au moins une question sur le congrès : celles qui n’ont répondu que lors de l’inscription sont exclues. Après fusion des jeux de données, 54 colonnes sont retenues pour nos analyses.
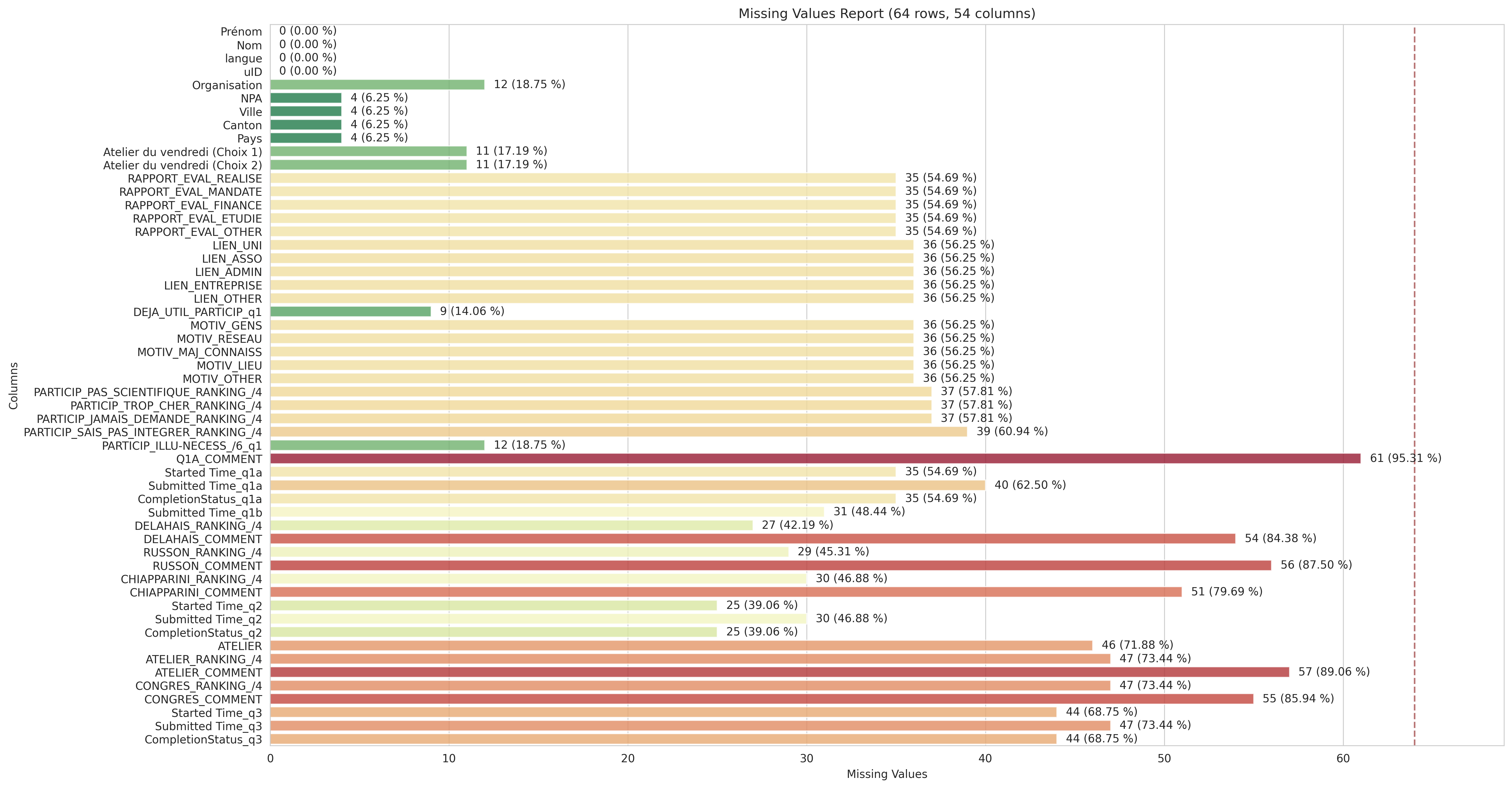
Comme il était possible de sauter des questionnaires ou des questions, plusieurs colonnes contiennent des valeurs nulles. Sans surprise, les commentaires restent les moins renseignés. Le graphique suivant résume les informations sélectionnées et leur taux de valeurs manquantes.
Les 54 colonnes retenues et leur taux de valeurs manquantes
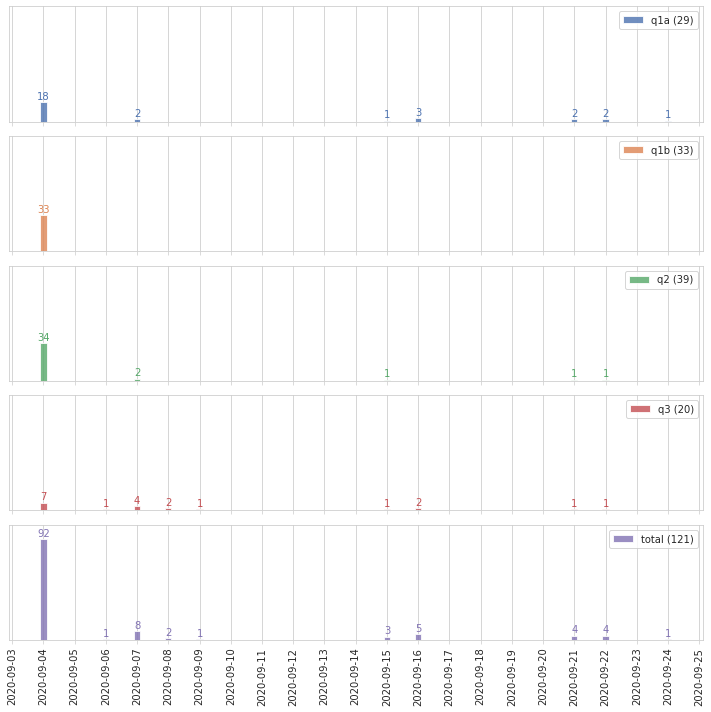
2.1 À quels moments les répondants ont-ils accédé aux questionnaires ?
Les répondants ont majoritairement ouvert leurs questionnaires le jour du congrès. Outre les slides ou les affiches lors du congrès, des liens ont été transmis par courriel le matin du congrès, ainsi que, pour les francophones, par relance les 15 et 21 septembre.
Dates des accès aux questionnaires
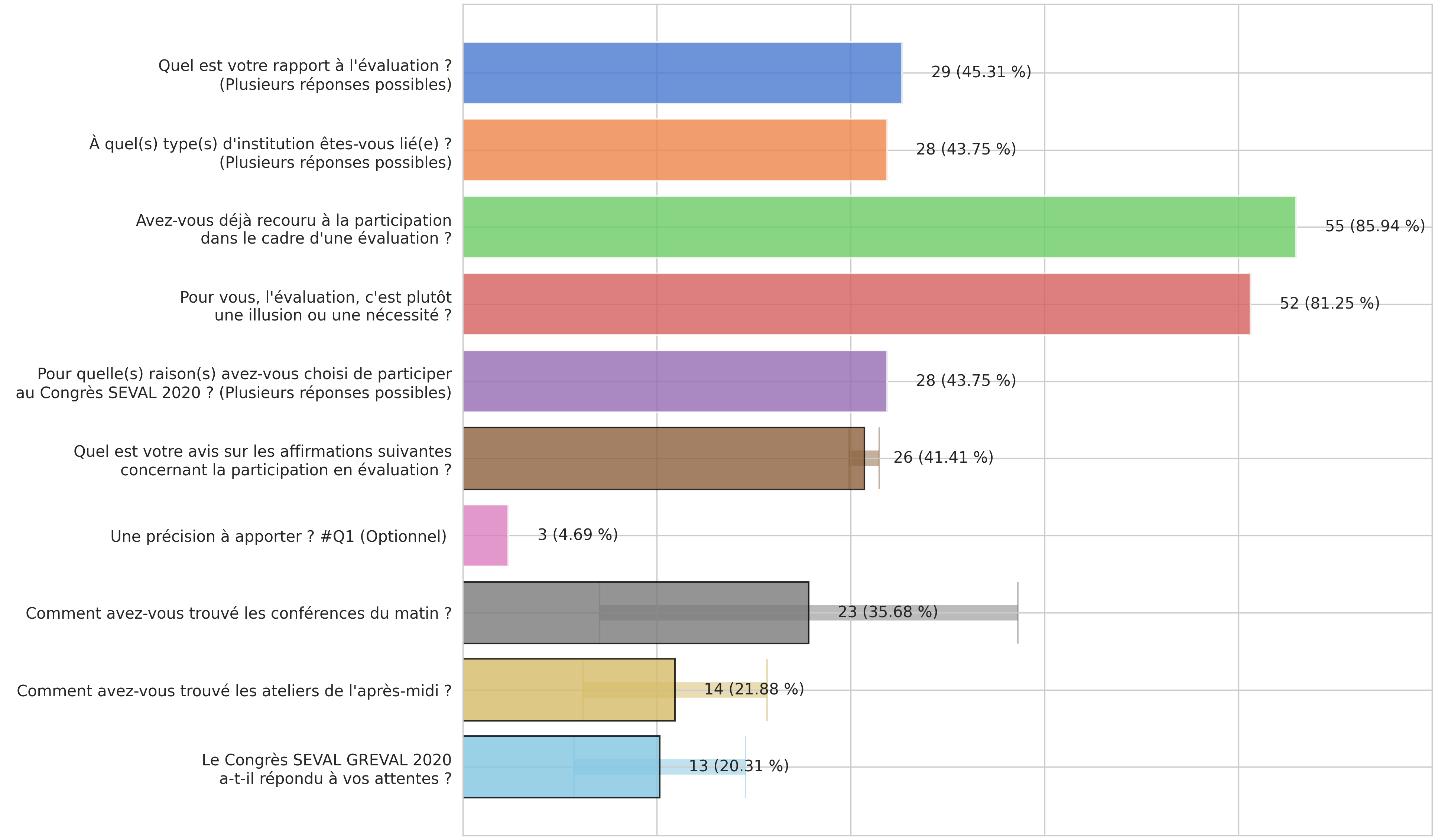
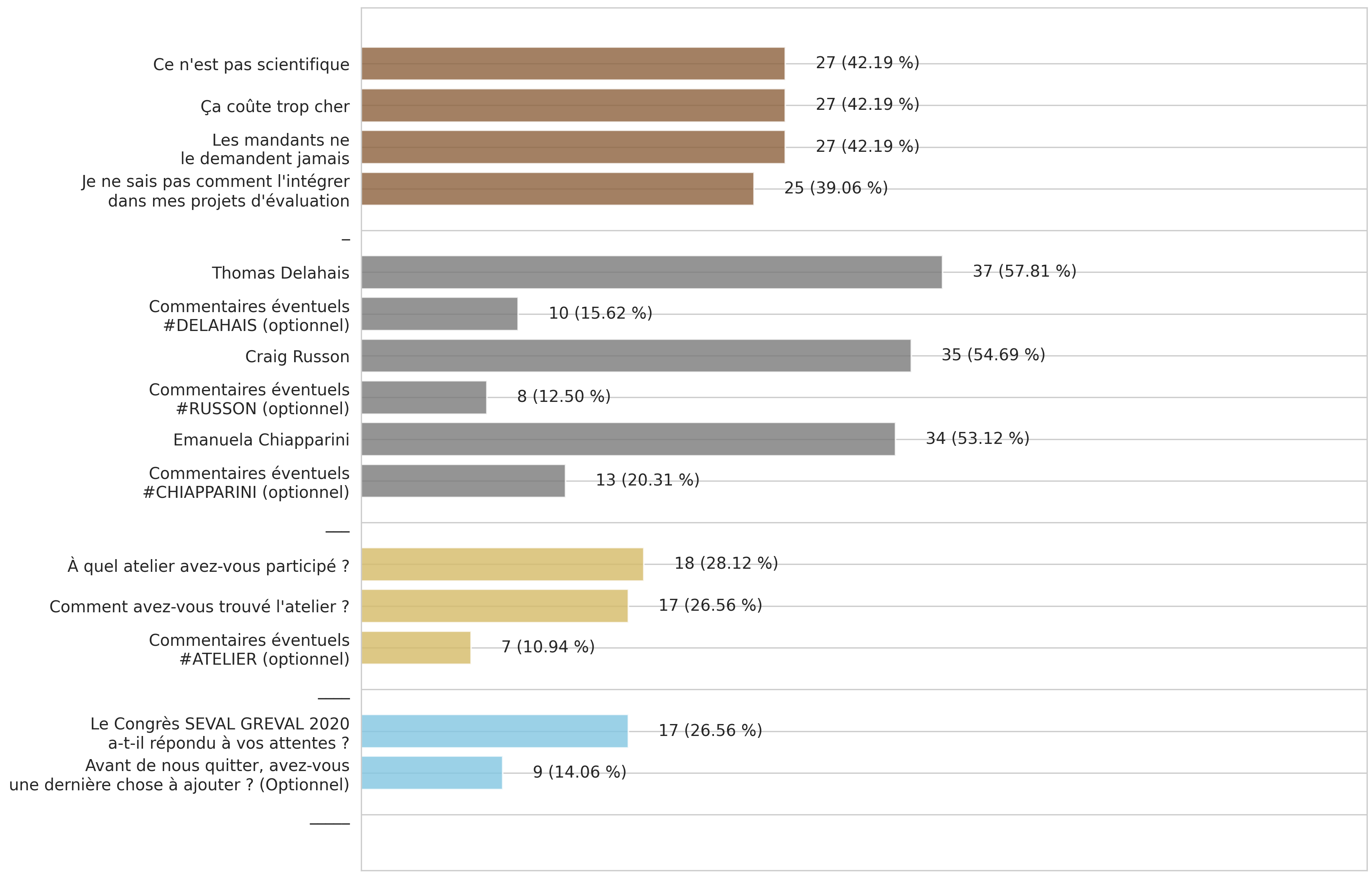
2.2 Quel taux de réponse par question ?
Les questions qui ont obtenues le plus de réponses sont celles qui ont été posées durant la session « icebreaker » (en vert et en rouge). Ce format mériterait d’être réexploité lors de nos prochains événements. Bien qu’ils soient moins renseignés, les commentaires optionnels ne sont pas systématiquement sautés. Peut-être que la précision demandée à la fin du questionnaire 1 (en rose) aurait pu être reformulée, si ce n’est retirée.
Notez que le questionnaire 2 (en gris) a bénéficié d’une invitation particulièrement active : à la fin du déjeuner, je me suis baladé auprès des participants avec les codes QR du questionnaire épinglés sur moi.

Taux de réponse par question (certaines sont moyennées)
… Taux de réponse des questions moyennées
À propos de Michael

Consultant
Data Science | Evaluation | Web Dev
Je travaille comme entrepreneur et comme conseiller en organisation depuis 2016. Je suis spécialisé en data science, en évaluation et en développement d’applications web. J’ai aidé plusieurs organisations à moderniser leurs processus de travail (notamment @ ![]()
![]()
![]()
![]() ) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
) et je cultive une passion sans borne pour ce que le numérique peut apporter à la réalisation de projets. À côté, je dirige Sympa Bonnard, un e-commerce qui promeut une consommation éthique et locale. Je trouve mon épanouissement en soutenant des organisations à développer et à améliorer leurs projets, tout en leur transmettant les outils pour développer leur propre autonomie.
![]() LinkedIn |
LinkedIn | ![]() YouTube |
YouTube | ![]() Écrivez-moi
Écrivez-moi
⬤ Vous êtes ici